|
Hello World! I'm a Research Scientist at Flawless AI developing the next generation facial animation. I received my Ph.D. from the Graduate School of Culture Technology (GCST) at KAIST, where I was advised by Prof. Junyong Noh. My research lies at the intersection of deep learning, computer vision, and computer graphics. Specifically, I am interested in generative AI, with a focus on animating 3D humans as well as manipulating images and videos. Email / CV / Google Scholar / Github / LinkedIn |

|
|
|
|
TOG 2025 paper / video Propose a latent-based landmark detection and latent manipulation module to edit the emotion of portrait video that faithfully follows the original lip-synchronization or lip-contact. |
|

|
Seonghyeon Kim, Changwook Seo, SIGGRAPH 2025; TOG 2025 A novel deep learning-based virtual oculoplastic surgery simulation system that aims to improve the accuracy and quality of simulations by considering the anatomical structure and characteristics of the eye. |
|
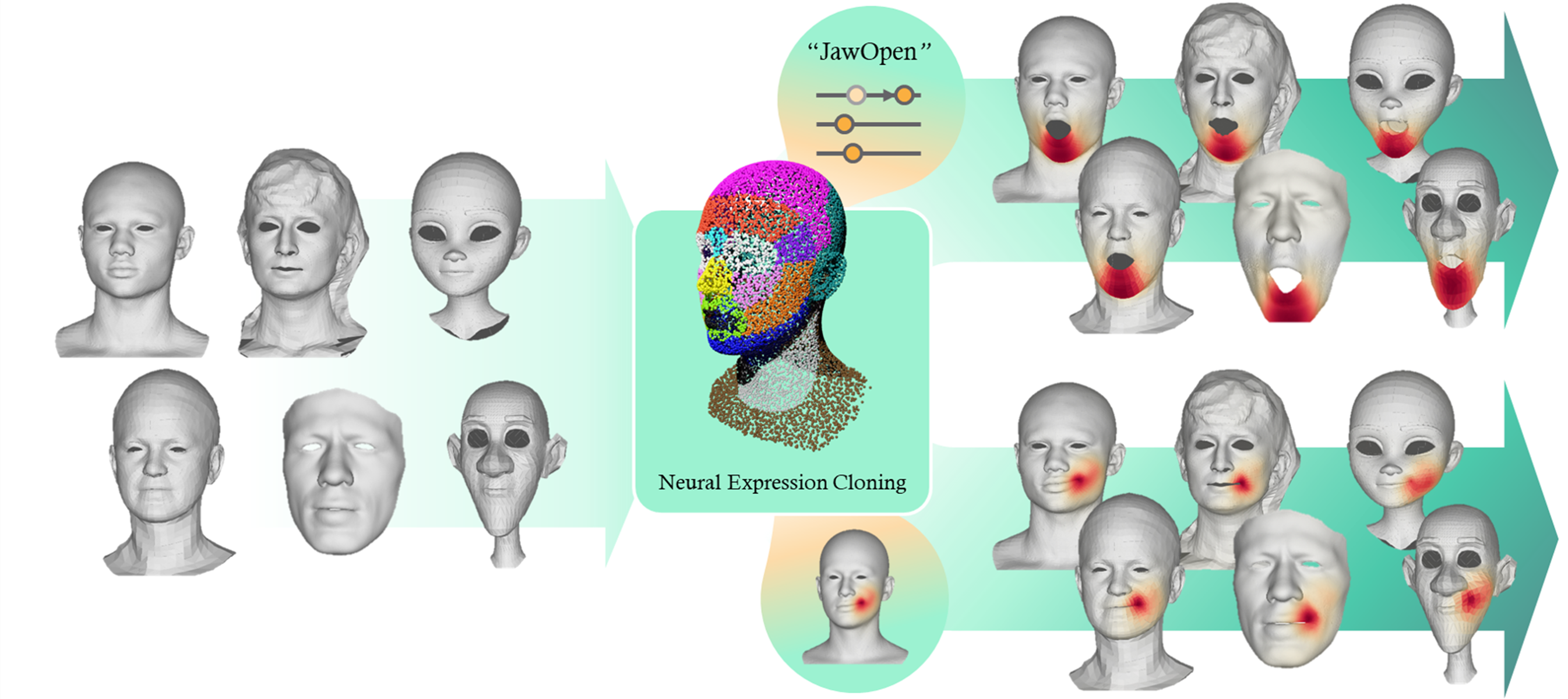
Sihun Cha, Serin Yoon, Eurographics 2025; CGF 2025 paper / page / video / code A method that enables direct retargeting between two facial meshes with different shapes and mesh structures. |
|
KCGS 2025 paper / video An end-to-end approach to animating a 3D face mesh with arbitrary shape and triangulation from a given speech audio. |
|
|
In submission paper / video Use a generative prior for identity agnostic audio-driven talking-head generation with emotion manipulation while trained on a single identity audio-visual dataset. |
|
|
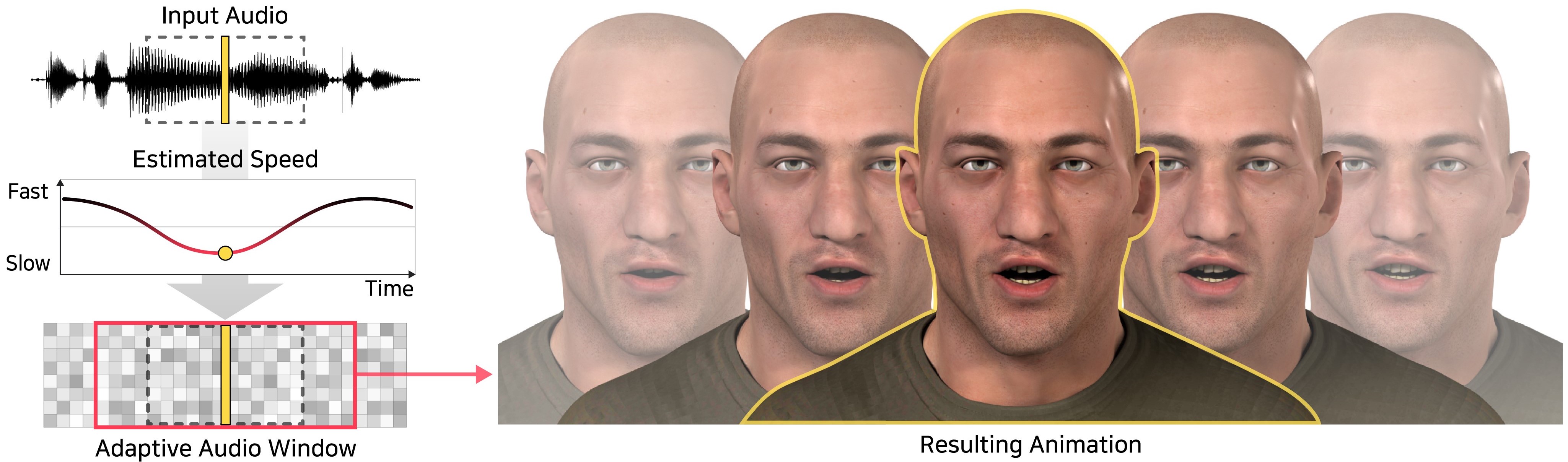
Sunjin Jung, Yeongho Seol, SIGGRAPH Asia 2024; TOG 2024 paper / video A novel method that can generate realistic speech animations of a 3D face from audio using multiple adaptive windows. |

|
Soyeon Yoon*, Kwan Yun*, CVPR 2024 paper / page / code Generate stylized 3D face model with a single example paired mesh by finetuning a pre-trained surface deformation network. |
|
Jongwoo Choi, CVPR 2024 paper / page / code Splatting deep generated features of pre-trained StyleGAN for cinemagraph generation. |
|

|
Kwan Yun*, Eurographics 2024; CGF 2024 paper / page / code / data Train a sketch generator with generated deep features of pre-trained StyleGAN to generate high-quality sketch images with limited data. |

|
Sihun Cha, Eurographics 2023; CGF 2023 paper / page / code Generating and completing of 3D human RGB texture from a single image using sampling and refinement process from visible region. |
|
Pacific Graphics 2022; CGF 2022 paper / page / code A method to edit portrait video using a pre-trained StyleGAN using the video adaptaion and expression dynamics optimization. |
|

|
Seonghyeon Kim, Sunjin Jung, Pacific Graphics 2021; CGF 2021 paper / video A novel unsupervised learning method by reformulating the retargeting of 3D facial blendshape-based animation in the image domain. |

|
JungEun Yoo*, CHI 2021 paper / video A method that generates a virtual camera layout for both human and stylzed characters of a 3D animation scene by following the cinematic intention of a reference video. |

|
Sanghun Park, SIGGRAPH Asia 2020; TOG 2020 paper / page / video / code A feed-forward neural network that can learn a semantic change of input images in a latent space to create the morphing effect by distilling the information of pre-trained GAN. |
|
|
|
|
Flawless AI Research Scientist Jun.2024-Current |
|
|
Visual Media Lab Research Assistance Jan.2017-Mar.2024 |
|
|
Adobe Research Research Intern Jun.2022-Aug.2022 Mar.2021-Jun.2021 |
|
|
NAVER Corp. Research Intern Dec.2019-Jun.2020 |
|
The source code of this website is from Jon Barron. (last update: Oct.22 2025) |